Your AI Prototype Is the Easy Part (No Offense)
A few weeks ago I had a call with a prospect about building an AI-native GTM pipeline. To prepare, I took the "just build" approach — scraped their pricing page to infer customer tiers, generated mock usage data for fifty free-tier accounts, set up a Clay trial to add a third-party enrichment research layer (find relevant company initiatives, hiring signals, funding activity), and rolled it up into property values and a weighted composite score that pushed to a CRM for reps. Built it over a weekend. Was pretty proud of it, honestly.
Turns out the prospect had already built their own version before we spoke. And theirs was better because it was built against their real data and shaped by their own domain expertise. (Should have seen that coming.)
I'm not saying my weekend prototype build was a waste of time — working through the problem hands-on made it easier to have a productive conversation (harden my infra opinions, ask good questions, etc.). But it clarified something I've been thinking about since:
Prototype generation is table stakes now. Everyone can spin one up. The differentiator is knowing what breaks when it hits production.
Enter AI Failure Taxonomies
To help answer that question, we have failure taxonomies: structured frameworks for categorizing how AI systems fail.
Failure taxonomies for agentic AI systems are more developed than most practitioners realize. Microsoft's AI Red Team published a detailed one. There's a NeurIPS 2025 paper — MAST — built from 1,642 execution traces across seven multi-agent systems. MAST covers agent coordination failures, hallucination, goal misalignment at the model and agent layer — that's serious work. What it doesn't address is the data pipeline integration layer underneath: what happens when your tools execute correctly, return valid responses, and the AI proceeds — but the data was never actually there.
I've been building a structured failure taxonomy focused on that layer — a framework for scoring risk across six dimensions before a workflow ships: blast radius, reversibility, frequency, verifiability, cascading risk, and composite score.
The goal is to surface the failures that don't announce themselves before they reach a customer. (I suspect those are the ones that cause the most real-world damage in production AI workflows.)
I ran v0 against my own CEO Agent system first (luckily I had several weeks of git logs to define known failure points to expect in the output). The first pass results were rough:
| Metric | Target | Actual |
|---|---|---|
| Tier 1 true positive rate | 100% | 62% (3 misses) |
| Tier 2 true positive rate | 90%+ | 66% |
| Tier 3 adversarial | 90%+ | 40% |
| False positive rate | <10% | 100% (all 3 "should-not-flag" items flagged) |
The headline: the tool needed calibration work. The scoring isn't where it needs to be yet.
Besides some tuning updates, that first run highlighted an interesting gap around silent failures. The taxonomy had modeled silent failure as "AI produces wrong output" — it never considered "data source returns valid-looking empty response," which is exactly what happened with the Zoho API parameter bug.
After tuning and extending the ghost data fix, I ran the updated tool against a completely different workflow type — the GTM sales pipeline prototype from the opening of this post. It caught all six documented failure modes — and then surfaced the same blind spot again, in a different context.
What v0.1 Caught (and What It Still Missed)
The tool caught the obvious risk immediately: AI-generated pricing proposals shown directly to customers without a human checkpoint. High blast radius, low reversibility, high frequency. That one was always going to surface.
It missed three things that would have caused real damage:
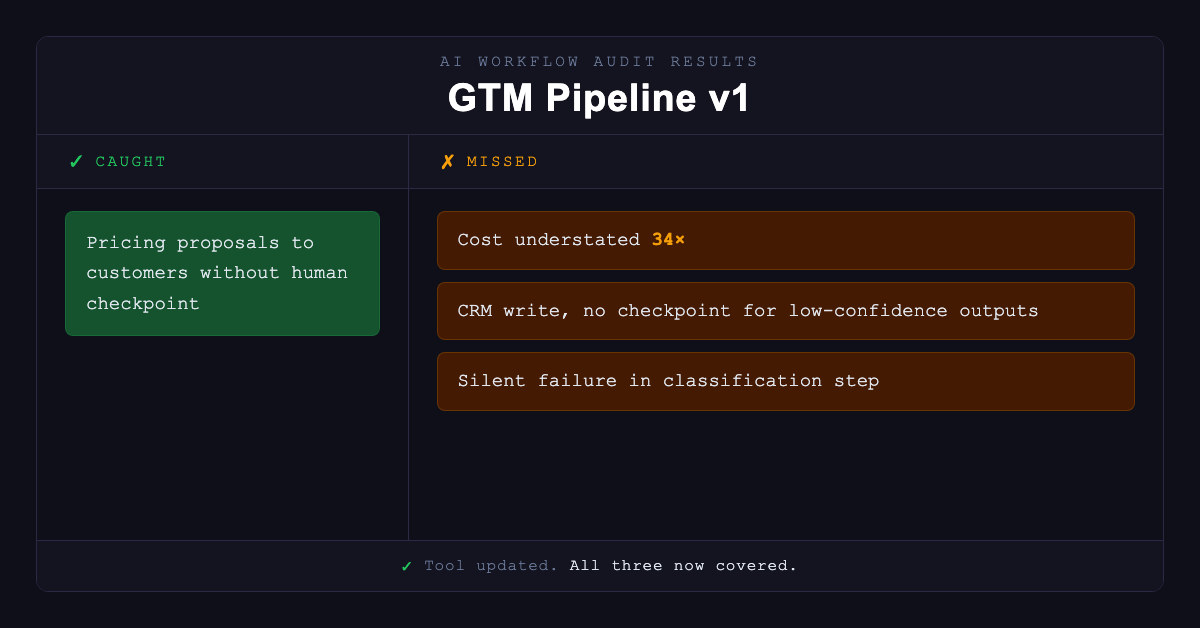
Cost underestimation by 34x
The model calculated per-call API costs accurately but didn't account for the batch processing multiplier. Projected infrastructure cost was off by an order of magnitude. (In a sales pipeline running on every lead, that math matters.) The audit had been scoring each step in isolation rather than accounting for how it would actually execute.
CRM write without a hard checkpoint
The pipeline was writing enriched account scores directly to HubSpot with no human review gate. Borderline accounts — the ones where the model was least confident — were being routed automatically. The audit flagged the step as medium risk but didn't catch that there was no fallback for low-confidence outputs. A rep would start working a lead the model wasn't actually sure about.
Silent failure in a classification step
This is the one that matters most, and I'll come back to it.
Each of these gaps would have cost a real sales team real money or real pipeline damage. That's the point of running the framework before production, not after.
The Failure Class the Existing Taxonomies Miss
The silent failure fix I'd already applied to data lookup steps — and then failed to extend to classification steps — points to a gap that the existing agent-level taxonomies don't address.
The existing frameworks focus on what the model does wrong. What they don't capture is what happens at the seam between your AI and your data sources. Specifically, there's a second class of silent failure that's harder to catch:
The tool executes successfully. The schema looks right. The AI has no signal that anything is wrong. But the substantive content is absent.
I'm calling this the ghost data failure class.
The CEO Agent was the first receipt. The GTM pipeline was the second — a propensity scoring step returning confident-looking output on a data source that had quietly stopped returning anything useful. Same class of failure, different domain, same blind spot in the taxonomy.
That's the punchline: the failure taxonomy you think is complete will have the same blind spot in every new domain until you test it against something real. The fix I applied after the Zoho bug was correct but narrow. I'd fixed the instance without fixing the pattern.
The underlying issue: verifiability scoring for data lookup steps was based on whether you can check the output — not whether an empty output reflects reality or a configuration failure. A response of {"messages": []} is verifiable in the sense that you received it. It's not verifiable in the sense that it reflects reality.
Where Ghost Data Shows Up
The ghost data failure class isn't unique to email integrations. It shows up anywhere a data source can return a valid-looking empty response:
- A CRM query returning zero contacts because the filter parameter is wrong
- A usage API returning zero events because the date range is off by one day
- A vector search returning zero results because the embedding model changed
- A webhook that stopped firing because a config was silently reset
In each case: downstream system receives valid output, proceeds normally, produces a result that looks reasonable. The failure is invisible until someone notices something important is missing — which, in a production AI workflow, might be days later.
The taxonomy extension: when scoring verifiability for any data lookup step, ask not just "can I check this output?" but "does an empty result reflect reality, or a configuration failure I can't see from here?" If you can't answer that from the step's output alone, the verifiability score should reflect that uncertainty.
Am I capturing every edge case? Probably not. But this is the version that would have caught the Zoho bug before I noticed the brief felt thin.
The Tool
The workflow audit CLI has five components: a six-dimension risk scorer, a failure-type mapper (now including ghost data as a named class), a checkpoint recommender, a cost calculator, and an eval suite that validates the scorer against documented failure cases.
I ran it against two real systems before publishing this — my own CEO Agent (where v0 exposed the calibration gaps) and the GTM pipeline prototype. The ghost data fix is in. The three gaps it surfaced in the GTM pipeline are real gaps that are now covered. Calibration work on the scoring is ongoing — the tool is useful now (hopefully) but obviously not finished.
The most valuable part of this process wasn't the tool itself — it was running it against real workflows and letting the gaps surface. Each new workflow type exposes blind spots the previous one didn't. If you have an AI workflow you'd be willing to run it against, I'd genuinely welcome the input. The taxonomy gets better with more surface area to test against.
The repo is public: github.com/kmflynn5/fds-ai-workflow-audit
Need help auditing your AI workflows?
The prospect in the opening had the prototype. What they needed was the framework to get it past the last mile. That's the work.
I help B2B SaaS companies assess and harden AI workflow pipelines before they reach production — or diagnose why they're failing after they do.
If you're shipping AI workflows and want a structured risk assessment before something breaks quietly, let's talk.